本文来自Windows核心编程总结,第二章。
主要讲了对Unicode的介绍和使用方法及建议。
这里主要是讲多字节字符串与宽字节字符串的转换…
2.1 字符编码
2.2 ANSI字符 和 Unicode字符 与字符串数据类型
2.3 Windows中的Unicode函数 和 ANSI函数
2.4 C运行库中的Unicode函数 和 ANSI函数
2.5 C运行库中的安全字符串函数
2.6 为何要用Unicode
2.7 推荐的字符和字符串处理方式
2.8 Unicode 和 ANSI字符串转换
2.1 字符编码:
字符编码 有ANSI、UTF-16、UTF-8、UTF-32等形式。
这里的UTF全称是 Unicode Transformation Format(Unicode 转换格式)
在谈到Unicode时,一般都是指UTF-16编码。
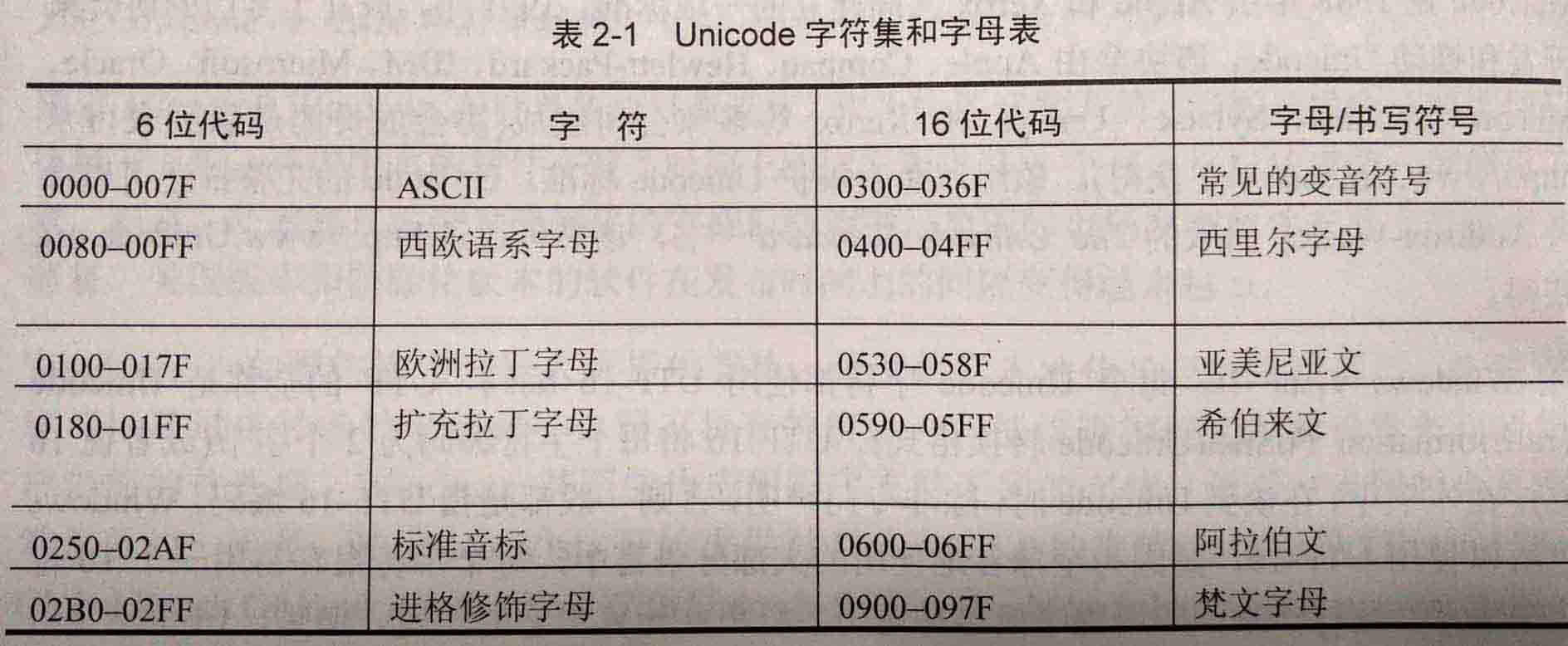
2.2 ANSI字符和Unicode字符与字符串数据类型:
char 表示8位ANSI字符
wchar_t 表示16位Unicode字符-需要指定 /Zc:wchar_t 编译器开关
字符串用 wchar_t szBuffer[100] = L”A String”; 类似这样定义即可
2.3 Windows中的Unicode函数和ANSI函数
如果Windows函数参数列表中有字符串,则一般有两个版本。
例如: CreateWidnowEx 函数,就有两个版本:
一个 CreateWindowExW 接受Unicode字符串
一个 CreateWindowExA 接受ANSI字符串
但是实际上我们只调用 CreateWindowEx ,因为它实际上时候这样定义的:
|
1 2 3 4 5 |
#ifdef UNICODE #define CreateWindowEx CreateWindowExW #else #define CreateWindowEx CreateWindowExA #endif // !UNICODE |
这是我在WinUser.h里面复制粘贴出来的…
所以编译的时候是由是否定义 UNICODE 来决定调用版本的。
2.4 C运行库中的 Unicode函数 和 ANSI函数
和Windows函数一样,C运行库也提供了一系列的函数来处理ANSI字符和字符串,并提供了另一系列的函数来处理Unicode字符和字符串。
然而它们在内部并不会相互转化。
例如,在C运行库中,strlen 是一个返回ANSI字符串长度的函数。与之对应的是 wcslen,这个C运行库函数能够返回Unicode字符串的长度。
这两个函数的原型都在 String.h中,然后它们还有一个宏,在TChar.h中:
|
1 2 3 4 5 |
#ifdef _UNICODE #define _tcslen wcslen #else #define _tcslen strlen #endif |
原理是同上的。
2.5 C运行库中的安全字符串函数
主要是 strcpy 和 wcscpy 函数的一些问题导致了不安全,为此提供了一些安全函数。
这里不详细介绍。
2.5.1 初识新的安全字符串函数
几乎现在的每一个函数都有了一个与之对应的新版本函数。
前面的名称都是相同的,但是在最后添加了一个_s的后缀。
我们来看一下他们的代码原型:
|
1 2 3 4 5 |
PTSTR _tcscpy( PTSTR strDestination , PCTSTR strSource ); errno_t _tcscpy_s( PTSTR strDestination , size_t numberOfcharacters , PCTSTR strSource ); PTSTR _tcscat( PTSTR strDestination , PCTSTR strSource ); errno_t _tcscat_s( PTSTR strDestination , size_t numberOfcharacters , PCTSTR strSource ); |
可以看到它们的区别就是,将一个缓冲区作为参数传递时,必须同时提供它的大小。
2.5.2 在处理字符串时如何获得更多控制
C语言库函数还新增了一些函数,用于执行字符串处理时提供更多控制。
例如我们可以填充控制符,指定截断等等。
2.5.3 Windows字符串函数
Windows也提供了很多字符串函数。
这里并不会重点讲。值得一看的是 CompareString
2.6 为何要使用Unicode…
- 有利于应用程序本地化
- 使用Unicode,只需要发布一个二进制文件,就可以支持所有语言
- 提升应用程序效率
- 可以调用尚未弃用的Windows函数,因为部分函数只支持Unicode
- 很容易与COM组件集成
- 很容易与 .NET Framework 集成
- 保证应用程序代码能轻松操作资源
2.7 推荐的字符和字符串处理方式
这里大致都是一些规则。
个人认为重要的是… 使用 MultiByteToWideChar 和 WideCharToMultiByte 函数完成 Unicode 和 ANSI字符串的转换
2.8 Unicode 与 ANSI字符串的转换
我们可以使用 MultiByteToWideChar 函数将多字节字符串转换为宽字节字符串
函数原型如下:
|
1 2 3 4 5 6 7 8 9 10 |
int WINAPI MultiByteToWideChar( _In_ UINT CodePage, _In_ DWORD dwFlags, _In_NLS_string_(cbMultiByte) LPCCH lpMultiByteStr, _In_ int cbMultiByte, _Out_writes_to_opt_(cchWideChar, return) LPWSTR lpWideCharStr, _In_ int cchWideChar ); |
还有一个是 WideCharToMultiByte 函数,将宽字节字符串转换为多字节字符串
|
1 2 3 4 5 6 7 8 9 10 11 12 |
int WINAPI WideCharToMultiByte( _In_ UINT CodePage, _In_ DWORD dwFlags, _In_NLS_string_(cchWideChar) LPCWCH lpWideCharStr, _In_ int cchWideChar, _Out_writes_bytes_to_opt_(cbMultiByte, return) LPSTR lpMultiByteStr, _In_ int cbMultiByte, _In_opt_ LPCCH lpDefaultChar, _Out_opt_ LPBOOL lpUsedDefaultChar ); |
以上都是直接拷贝出来的源码…这里会进行详细讲解:
首先是 MultiByteToWideChar :
|
1 2 3 4 5 6 7 8 |
int MultiByteToWideChar( UINT CodePage , //标识了与多字节字符串关联的代码页值 DWORD dwFlags , //允许我们进行额外控制 PCSTR lpMultiByteStr , //要转换的字符串 int cbMultiByte , //字符串长度 LPWSTR lpWideCharStr , //缓冲区 int cchWideChar //缓冲区长度 ); |
如果为 cchWideChar参数传入0,函数就不会执行转换,而是返回一个宽字符数。
所以可以用一下步骤进行转换:
- 调用MultiByteToWideChar,为pWideCharStr参数传入NULL,为cchWideChar参数传入0,为cbMultiByte参数传入-1
- 分配一块足够容纳转换后的Unicode字符串的内存。它的大小是上一个MultiByteToWideChar调用的返回值乘以sizeof(wchar_t)后的值。
- 再次调用MultiByteToWideChar,这一次将缓冲区地址作为pWideCharStr参数的值传入,将第一次MultiByteToWideChar调用的返回值乘以sizeof(wchar_t)的大小作为cchWideChar参数的值传入。
- 使用转换后的字符串
- 释放Unicode字符串占用的内存块
对应的,我们可以这样来用 WideCharToMultiByte 函数。
要注意的是多了两个参数:
|
1 2 3 4 5 6 7 8 9 10 |
int WideCharToMultiByte( UINT CodePage , //关联代码页 DWORD dwFlags , //额外控制 PCWSTR pWideCharStr , //宽字节字符串 int cchWideChar , //长度 PSTR pMultiByteStr , //多字节字符串 int cbMultiByte , //缓冲区大小 PCSTR pDefaultChar , //一般传入NULL PBOOL pUsedDefaultChar //一般传入NULL ); |
2.8.1 导出ANSI 和 Unicode DLL函数
这里不阐述
2.8.2 判断文本是ANSI还是Unicode
IsTextUnicode 函数即可